

人形机器人"网球运动员"来了 高动态精准击球!网球是人形机器人面临的一大挑战。高速来球要求瞬时判断,全身协调决定回球质量,全场奔跑考验爆发力与控制力。当机器人站上球场,能否像人类运动员一样完成判断、移动与连续回击?

画面显示,机器人迅速调整站位,上下半身协同挥拍击球,并将球精准回击到指定位置。面对各种来球,它能够持续调整身体姿态与击球时机,与不同水平的对手完成多回合对拉。
在高动态、高对抗环境中,机器人需要应对时速超过几十公里的来球、变幻莫测的落点轨迹以及不断变化的击球节奏。更重要的是,这一能力并非依赖预编程动作实现,而是通过深度强化学习自主习得。这是全球首次在人形机器人上实现高动态网球对打,标志着从“机械复刻动作”向“智能决策响应”的跨越。
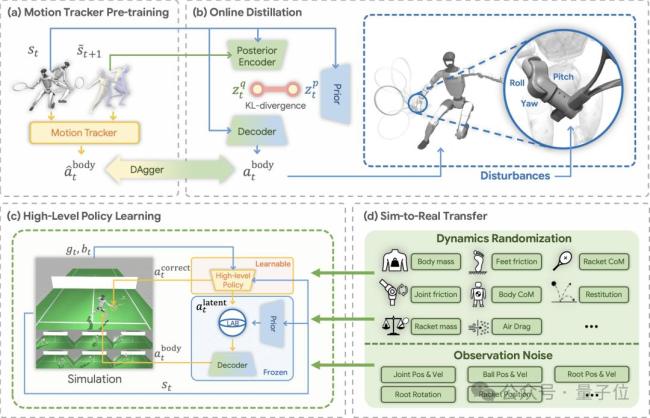
研究团队提出了一种新的机器人运动学习方法,使人形机器人能够从不完美的人类动作数据中学习复杂的运动技能,并在真实世界中完成高动态、高敏捷的网球击球与对打任务。传统的人形机器人运动学习依赖高质量遥操作数据进行模仿学习,但在网球这样的高动态场景中,这类数据几乎难以获取。而通过高质量动作捕捉数据完整记录一场网球比赛涉及的人体运动,则需要高精度、大范围的动作捕捉系统,且非常昂贵。
LATENT提供了一种完全不同的思路:不依赖昂贵且难以获得的网球全场比赛跑动数据和精准的运动员击球手部动作,仅靠收集前后移动、正反手挥拍、横向步伐等碎片化动作,让机器人自主学习运动技能空间,构建其“运动小脑”,从而解锁大范围跑动急停、回击各种来球的能力。

团队把难以规模化采集的完美专家数据替换为易获取但不完美的人类动作数据,从源头打开机器人运动技能学习的数据通路。研究团队提出在隐空间中构建一个“运动技能空间”,将碎片化的人类动作先验组织为可组合、可泛化的技能结构。通过在训练过程中对关键自由度施加随机扰动,该空间允许关键自由度上可被修正、可探索。这使机器人不再只是机械复刻训练数据,而是获得既保留自然运动风格又允许击球细节被修正的技能表示。
在训练过程中,强化学习驱动的规划器会在这一技能空间中进行采样与组合。面对不同来球,机器人可以根据球速、落点以及自身姿态,对步伐、挥拍节奏和身体姿态进行实时自主规划,在保持自然运动风格的同时实现稳定击球。此外,机器人还会根据实时感知对动作进行微调,特别是在击球末端自主修正挥拍轨迹,从而控制回球方向与落点,使回击更加稳定、精准。

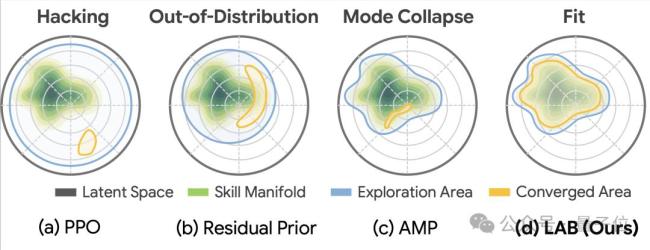
为了避免机器人找到一些“投机取巧”的策略,如通过抖动、不自然的动作勉强击中来球,研究团队提出了隐空间动作屏障Latent Action Barrier(LAB)。LAB为强化学习提供了一种受约束但不僵化的探索机制。策略可以针对不同来球、自主跑位以及击球动作进行灵活调整,但同时不会轻易偏离自然的人类运动模式。因此,在训练过程中,机器人既能保持自然稳定的运动风格,又能逐渐学会适应不同来球情况,实现更加精准的击球控制。
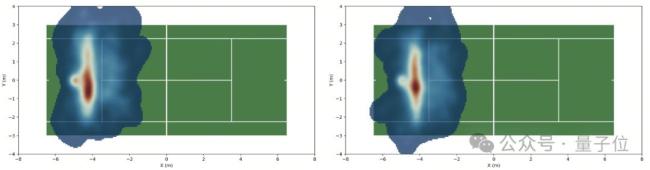
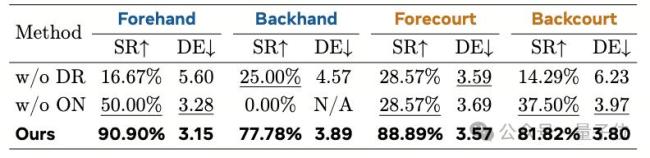
为了验证LATENT的性能,研究通过将策略部署至29自由度的宇树G1机器人,并在MuJoCo仿真器和真实世界中进行了大量测试。实验对比了LATANT与经典基线算法如PPO、AMP的性能表现。结果显示,LATENT在击球成功率、回球落点精准性、关节顺滑程度与关节力矩上均表现出色。在真实物理世界中,研究者进行了连续20局的人类-机器人连续网球对拉,涵盖多种实验设置。实验证明,LATENT在不同球场位置、不同击球动作的表现下均有较高的击球成功率和击球精准度。
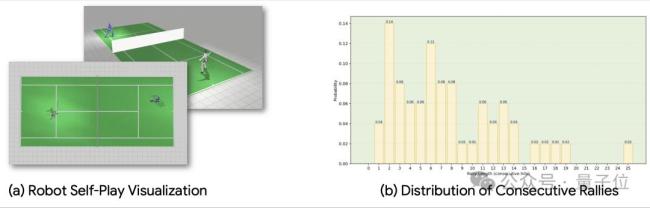
研究团队还展示了两个机器人之间的连续对练场景。这为未来机器人的自主学习与持续能力进化带来了更多想象空间。当机器人能够像人类一样移动、判断并完成复杂运动任务时,人形机器人的应用边界将进一步扩展。从运动娱乐到家庭服务,再到各种复杂的人机协作场景,具身智能正在逐渐走出实验室,进入真实世界。
网眼查提示:文章来自网络,不代表本站观点。







